The Foldr server can process and analyse image files and documents containing graphical elements to extract text that is then searchable by users. The Optical Character Recognition (OCR) process can be performed either using the Foldr server’s built-in OCR engine (Tesseract), or cloud OCR engines hosted by AWS (Textract) and Google Vision.
This article assumes that Search has already been configured on the Foldr server. This is covered by the following KB article
Creating the AWS IAM/user for Textract
Log into the Amazon AWS console with a suitable administrative account

In the Search for services bar, search for IAM – then select IAM from the results
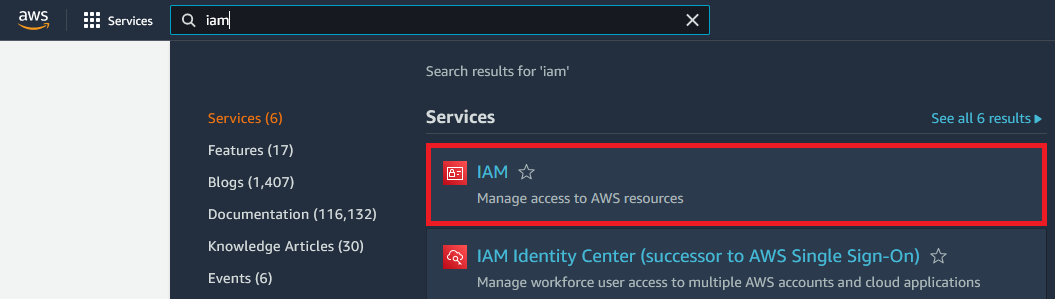
Click Users
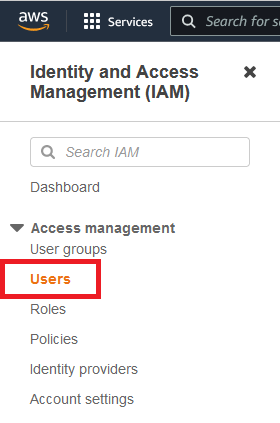
Click Add Users (found on the right of the screen)

Give the user a suitable Username and select Access Key – Programmatic Access as the AWS credential type
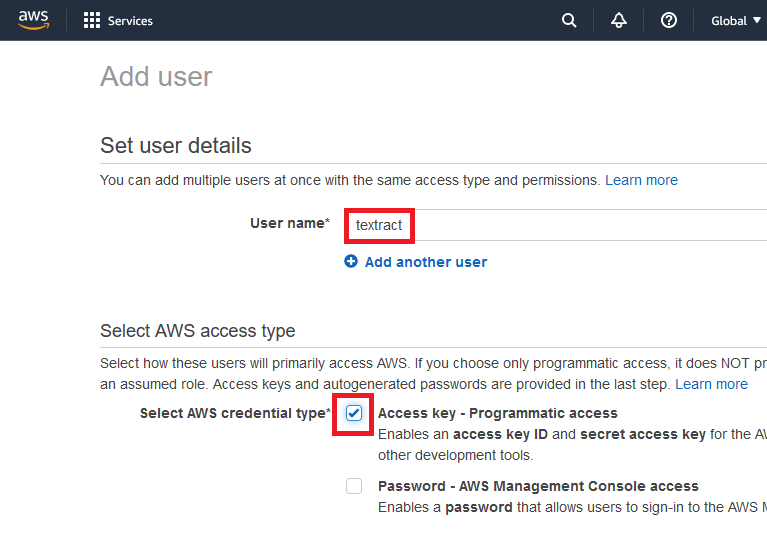
Click Next: Permissions
![]()
Click Attach existing policies directly
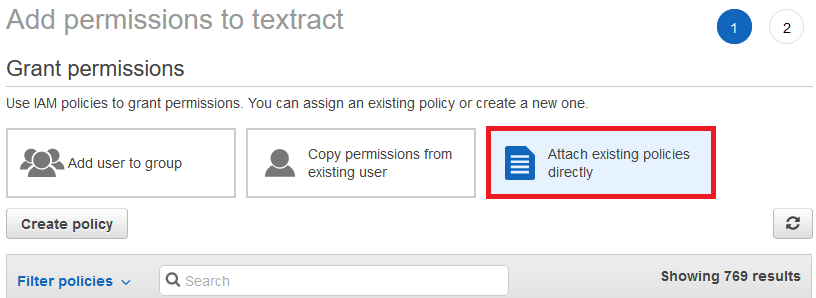
Filter the permissions and add the following:
AmazonSNSFullAccess
AmazonTextractFullAccess
AmazonS3FullAccess
Click Next: Tags
![]()
Click Next: Review
![]()
The create user and permission summary will be shown
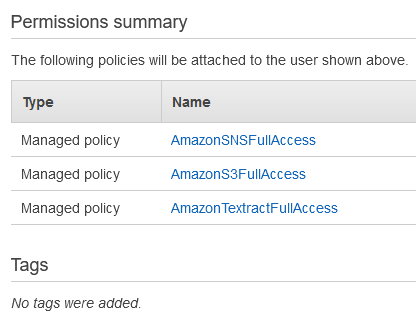
Click Create User
![]()
A success message will be shown

Below the success message, the Access Key ID and Access Secret are shown. Click the ‘show’ link to display the secret and make a note of both values.
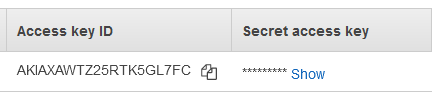 ~
~
Create Foldr Service Account
A Service Account for the Textract OCR process should now be configured in Foldr Settings.
Select Integrations in the Foldr web admin interface
Click the Service Accounts tab
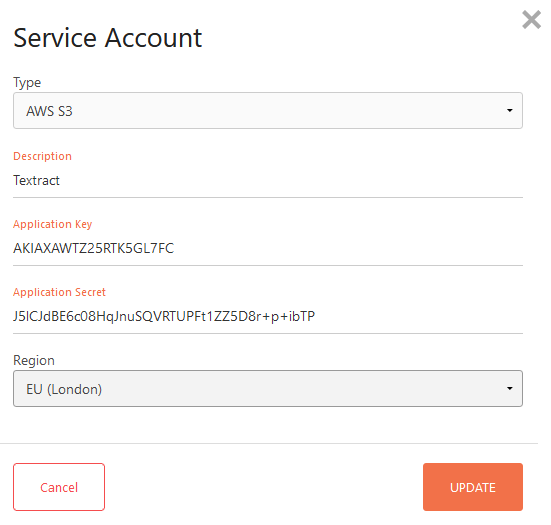
Click + Add New and configure the service account.
Type = AWS S3
Enter the Application Key (Access Key ID) and Application Secret (Secret Access Key) as shown in AWS Console.
Select the appropriate Region and click Update
Enable Textract OCR on the storage item/share
Within Foldr Settings, select Files & Storage and edit the appropraite storage item.
Selet the Search and Data tab and then select Settings
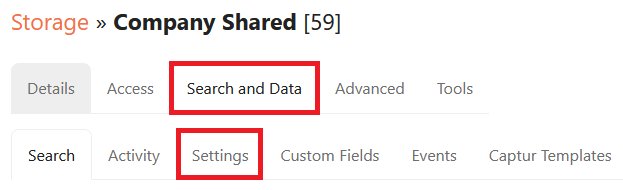
In the Crawl tab, scroll down and enable the toggle Index file contents
Now, select the OCR tab (top of screen)
Select the Enable OCR toggle, select AWS Textract as the OCR Engine and the Textract service account.
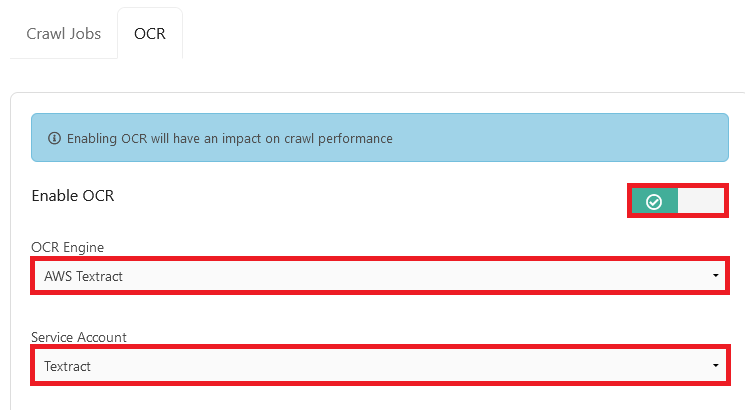
Click Save Changes
The AWS Textract integration is now complete and an initial crawl can be started by the administrator by clicking the Search and Data > Activity tab > + Crawl Now. Additionally, all files now uploaded to this storage item will be indexed by the Foldr server and processed by AWS Textract for OCR.
Note – All SMB shares will require a suitable service account to be configued and selected under Foldr Settings > Files & Storage > Access tab. The service account neesd read permission to the SMB share and files contained within and should use the account UPN (username@domain.fqdn format) for its username.